Dein ITSM-Dashboard lügt
Es ist Donnerstagmorgen, Jour fixe. Der Service-Desk-Leiter zeigt seine Folie: "Kapazitätsengpass SAP Basis — 7.800 Stunden Impact, 1.8x über Peer-Median." Die Reaktion am Tisch: besorgte Blicke. Der CIO fragt: "Was tun wir dagegen?" Die Antwort: "Wir haben das SAP-Team verstärkt." Drei Wochen später: Der Impact ist um 9% gesunken. Die 7.800 Stunden kamen zu 69% aus einem einzigen Bereich — aber die restlichen 31% verteilten sich auf zwei weitere Teams, die niemand adressiert hat. Das Dashboard hat nicht gelogen. Es hat nur das Falsche gezeigt.
Das Problem mit der einen Zahl
Dashboards fassen zusammen. Das ist ihre Aufgabe. Aber Zusammenfassung bedeutet Informationsverlust — und genau dieser Verlust führt zu falschen Entscheidungen.
Nehmen wir eine typische Dashboard-Kachel: "Kapazitätsengpass — 7.8k h Gesamtauswirkung, 14 Findings, +18% Trend." Was sagt diese Zahl? Dass es ein großes Problem gibt. Was sie nicht sagt: Wo genau der Impact sitzt. Ob ein Team 69% des Problems verursacht und zwei andere je 5%. Ob die 1.8x-Abweichung von einem einzelnen Ausreißer kommt oder breit verteilt ist. Ob die Handlung "SAP-Team verstärken" oder "Routing-Regeln prüfen" lauten müsste.
Ein IT-Manager, der eine einzelne Zahl sieht, bildet ein mentales Modell. Und dieses Modell ist fast immer falsch — nicht weil der Manager schlecht analysiert, sondern weil eine einzelne Zahl mehrere fundamental verschiedene Problemtypen abbilden kann.
Drei Probleme, eine Zahl
Hinter "7.800 Stunden Impact" können sich mindestens drei verschiedene Realitäten verbergen:
Dominanter Ausreißer: Ein Team ist extrem langsam (84 Tickets, 5.0x Abweichung). Der Impact konzentriert sich auf einen Punkt. Die Handlung ist klar: Dieses eine Team adressieren.
Schwerpunkt mit Tail: Ein Team trägt 69% des Impacts (5.300 Stunden), aber es gibt einen langen Schwanz aus kleineren Beiträgen. Wer nur den Hauptverursacher adressiert, löst zwei Drittel des Problems. Wer den Rest ignoriert, wundert sich in drei Monaten, warum die Zahl nicht runtergeht.
Breit verteilt: Fünf Teams tragen je 15-25% bei. Kein einzelnes Team ist "schuld." Das Problem ist systemisch — vielleicht ein Routing-Fehler, eine falsche Kategorisierung, ein Prozessschritt, der alle gleichermaßen betrifft. Die Antwort "mehr Leute für Team X" löst hier gar nichts.
Das Dashboard zeigt in allen drei Fällen dasselbe: Eine Zahl, einen Trend, eine Farbe.
Was passiert, wenn man hinschaut
Stell dir vor, statt einer Kachel siehst du das hier:
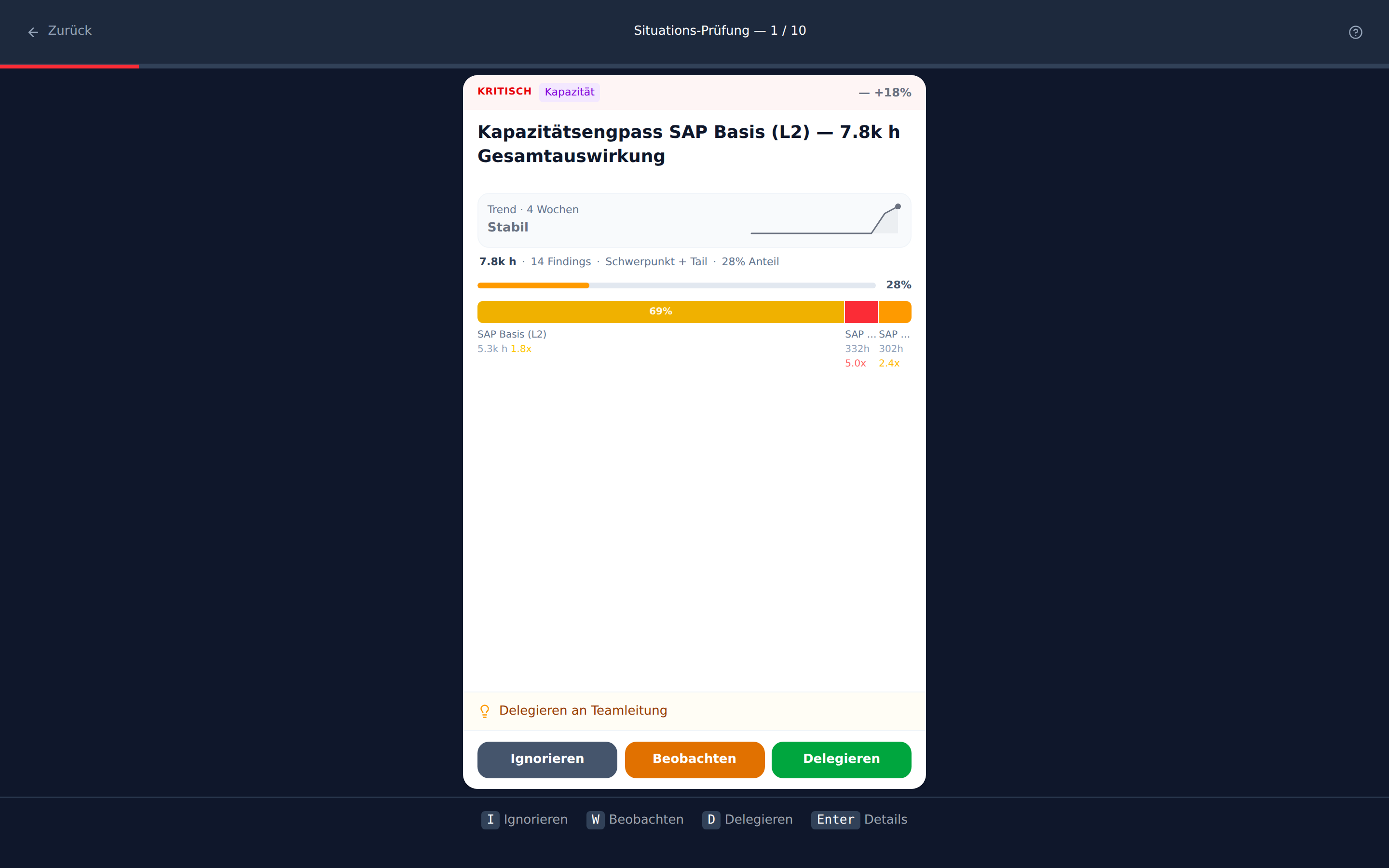 Die Blockbreite zeigt den Impact-Anteil jedes Bereichs. Die Farbe zeigt die Abweichungsstärke. Oben: der Gesamtanteil am System-Impact (28%). Darunter: die Verteilung auf die Verursacher.
Die Blockbreite zeigt den Impact-Anteil jedes Bereichs. Die Farbe zeigt die Abweichungsstärke. Oben: der Gesamtanteil am System-Impact (28%). Darunter: die Verteilung auf die Verursacher.
Was du sofort erkennst: SAP Basis (L2) trägt 69% des Impacts — 5.300 Stunden bei 1.8x Abweichung. Das ist der Schwerpunkt. Aber rechts davon sitzen zwei weitere Blöcke: kleinere Beiträge mit 5.0x und 2.4x Abweichung. Die sind im Volumen klein, aber in der Intensität hoch.
Das Shape-Label "Schwerpunkt + Tail" sagt dir auf einen Blick: Es gibt einen Hauptverursacher, aber auch einen relevanten Rest. Die Handlung ist eine andere als bei "Dominanter Ausreißer" — du musst beides adressieren.
Das ist keine Frage besserer Technik. Es ist eine Frage der Darstellung: Zeigst du eine Summe oder eine Verteilung?
Warum das in der Praxis schiefgeht
In realen ITSM-Organisationen mit 10-15 Bearbeitungsrollen passiert das ständig. Ein Service-Desk-Leiter sieht "Bearbeitungsverzögerung Network Ops — 8.400 Stunden Impact" und delegiert ans Netzwerk-Team. Das Team prüft seine Zahlen, findet einen moderaten Engpass, behebt ihn. Vier Wochen später: Der Impact ist um 12% gesunken. Der Rest steckt in nachgelagerten Kaskaden — SAP Basis staut auf, weil Network Ops verzögert, und Identity Management staut auf, weil SAP Basis staut. Drei Teams, eine Ursache, aber das Dashboard zeigt drei separate Probleme.
Die Verbindung zwischen den Teams — die Kaskade — ist in keinem Team-Dashboard sichtbar. Sie zeigt sich nur, wenn man Inflow und Outflow über Rollengrenzen hinweg betrachtet. Bei SAP Basis kommen 229 Tickets pro Woche rein, aber nur 92 gehen raus. I/O-Ratio: 2.49x. Der Backlog wächst um 111%. Und dieser Stau pflanzt sich weiter fort bis ins Identity Management, mit 100% Korrelation.
Das ist kein exotisches Szenario. Das ist Alltag in jeder Organisation, in der mehr als zwei Teams Tickets bearbeiten.
Die Frage, die du ab morgen stellen kannst
Du brauchst kein neues Tool, um besser zu entscheiden. Du brauchst eine bessere Frage.
Wenn dir das nächste Mal jemand eine Kennzahl präsentiert — "Durchlaufzeit 4.5x über Median", "SLA-Quote bei 73%", "Backlog +40%" — frag: Über wie viele Einheiten ist das aggregiert? Und wie ist die Verteilung?
Ist es ein Durchschnitt über fünf Teams, von denen eines extrem ist? Ist es eine Summe, bei der ein Bereich 70% beiträgt? Oder ist es gleichmäßig verteilt? Die Antwort verändert die Handlung fundamental.
Und wenn du sehen willst, wie das mit deinen eigenen Ticket-Daten aussieht: Process Radar macht genau diese Zerlegung automatisch — Daten verbinden, Verteilung sehen, handeln.
Dieses Thema vertiefen: ITSM-Kennzahlen richtig lesen: Was unter der Oberfläche liegt
Wo steht Ihr Service Desk im Branchenvergleich?
Der ITSM Health Check zeigt es in 2 Minuten – fünf Eingaben, keine Registrierung.
Health Check starten