Dein Service Desk ist ein System — warum du ihn aber wie eine Sammlung von Silos behandelst
Der Service-Desk-Leiter hat gerade zwei FTE für den 1st Level genehmigt bekommen. Drei Monate später: Die Durchlaufzeit ist gleich geblieben. Warum? Die neuen Mitarbeiter bearbeiten mehr Tickets — 453 pro Woche statt 380. Aber der Backlog wächst trotzdem: +100 pro Woche. Denn die Ping-Pong-Rate zwischen 1st Level und Netzwerk ist von 12% auf 18% gestiegen. Jedes zusätzliche Ticket, das L1 schneller anfasst, bounced schneller zurück. Das System absorbiert die Kapazität. Mehr Leute, gleiche Durchlaufzeit. Das ist kein Paradox. Das ist Physik.
Die Silo-Falle
Wenn ein Team langsam ist, liegt die naheliegendste Erklärung beim Team: zu wenig Leute, zu komplexe Tickets, zu viele Unterbrechungen. Die naheliegendste Lösung: mehr Leute, einfachere Tickets, weniger Unterbrechungen.
Manchmal stimmt das. Oft stimmt es nicht.
Ein Team, das 229 Tickets pro Woche empfängt und 92 abarbeitet, hat ein Kapazitätsproblem — auf den ersten Blick. Aber warum empfängt es 229 Tickets? Kommen die alle von Endusern? Oder werden 40% von einem vorgelagerten Team weitergeleitet, das sie eigentlich selbst hätte lösen können? Sind es die richtigen Tickets, oder landen sie hier wegen einer pauschalen Routing-Regel?
Diese Fragen kann ein Team nicht beantworten. Es sieht seinen Eingang und seinen Ausgang. Es sieht nicht, warum der Eingang so hoch ist. Und es sieht nicht, was mit seinen Tickets passiert, nachdem es sie weitergeleitet hat.
Das ist die Silo-Falle: Jedes Team optimiert seinen Ausschnitt. Und niemand sieht das Ganze.
Stock und Flow: Die Sprache der Systeme
Jede Bearbeitungsrolle in einem Service Desk ist ein Bestand — ein Stock — mit Zufluss (Inflow) und Abfluss (Outflow). Das ist keine Metapher. Das ist messbar.
Wenn der Inflow größer ist als der Outflow, wächst der Bestand. Tickets stauen sich. Die Durchlaufzeit steigt. Das ist keine Meinung, das ist Arithmetik. Und es ist von außen nicht sichtbar, wenn man nur Durchlaufzeiten pro Team misst.
Ein Team kann eine exzellente Durchlaufzeit haben und trotzdem ein Systemproblem verursachen — nämlich dann, wenn es Tickets schnell weiterleitet statt sie zu lösen. Im Team-Dashboard sieht es vorbildlich aus. Im Gesamtsystem ist es die Ursache des Staus beim nächsten Team.
Was die Flow-Analyse zeigt
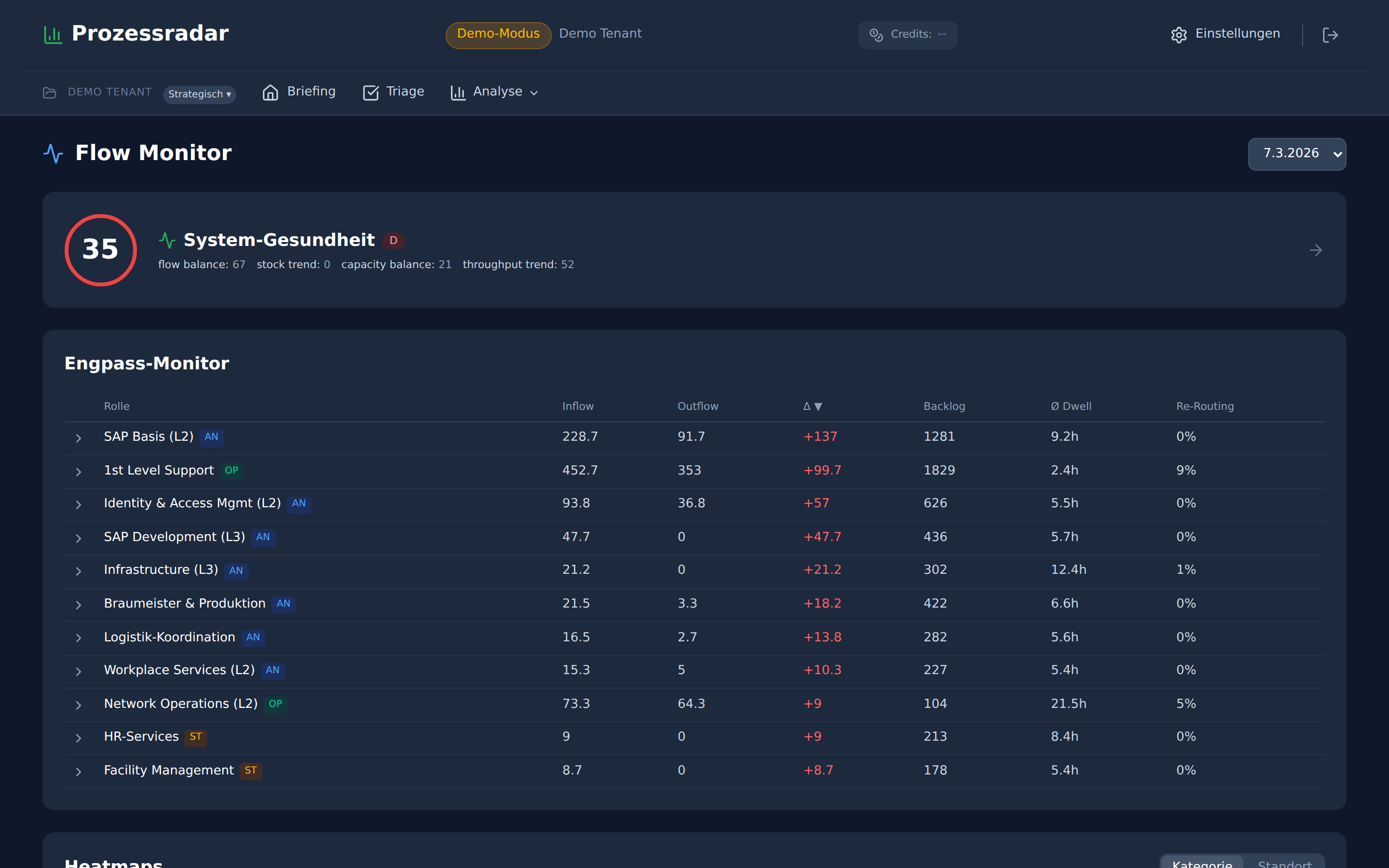 Der Engpass-Monitor zeigt pro Rolle: Inflow (Tickets/Woche), Outflow, Backlog-Veränderung (Delta), absoluten Backlog, durchschnittliche Verweildauer und Re-Routing-Anteil. Die Farben der Role-Badges (AN = Anomalie, OP = Operativ, ST = Stabil) zeigen den Gesamtzustand.
Der Engpass-Monitor zeigt pro Rolle: Inflow (Tickets/Woche), Outflow, Backlog-Veränderung (Delta), absoluten Backlog, durchschnittliche Verweildauer und Re-Routing-Anteil. Die Farben der Role-Badges (AN = Anomalie, OP = Operativ, ST = Stabil) zeigen den Gesamtzustand.
Was du hier sofort erkennst:
SAP Basis (L2): Inflow 228.7, Outflow 91.7 — Delta +137 pro Woche. Der Backlog steht bei 1.281 Tickets. Hier kommt 2.5x mehr rein als rausgeht. Das ist kein schlechtes Quartal. Das ist ein strukturelles Ungleichgewicht.
1st Level Support: Inflow 452.7, Outflow 353 — Delta +99.7. Der Backlog wächst ebenfalls, aber die Verweildauer ist mit 2.4 Stunden niedrig. L1 arbeitet schnell, aber 9% der Tickets werden re-routed. Diese 9% landen bei SAP Basis, bei IAM, bei Infrastructure — und tragen dort zum Stau bei.
Identity & Access Mgmt (L2): Inflow 93.8, Outflow 36.8 — Delta +57. Verweildauer 5.5 Stunden. Kein dramatisch hoher Einzelwert. Aber der Outflow ist weniger als die Hälfte des Inflows. In zehn Wochen verdoppelt sich der Backlog.
SAP Development (L3): Inflow 47.7, Outflow 0 — Delta +47.7. Null Outflow. Alles, was hier ankommt, bleibt liegen. 436 Tickets im Backlog, 5.7 Stunden Verweildauer. Und woher kommt der Inflow? Überwiegend von SAP Basis — das Team, das selbst schon staut.
Der Kaskadeneffekt
Das ist der Punkt, an dem Silo-Denken scheitert. SAP Basis staut → die Tickets, die SAP Basis an SAP Development weiterleitet, kommen verzögert an → SAP Development staut → die Rückmeldungen an SAP Basis verzögern sich → SAP Basis staut noch mehr.
Diesen Kreislauf sieht kein Team-Dashboard. Er zeigt sich nur, wenn man den Flow über Rollengrenzen hinweg betrachtet. Und die Daten bestätigen es: Die Korrelation zwischen dem Aufstau bei SAP Basis und dem Aufstau bei Identity Management liegt bei 100%. Wenn SAP Basis staut, staut IAM. Immer.
Das bedeutet: Wer IAM-Kapazität aufbaut, ohne den SAP-Basis-Stau zu lösen, baut Kapazität auf, die sofort wieder aufgefressen wird. Die Tickets kommen weiterhin schneller rein als raus — sie kommen nur von einer anderen Quelle.
Warum mehr Leute oft nicht hilft
Die intuitive Reaktion auf einen Engpass: Kapazität erhöhen. Mehr Mitarbeiter, mehr Budget, mehr Schichten. Manchmal ist das richtig. Aber in einem vernetzten System kann Kapazität an der falschen Stelle das Problem verschärfen.
Beispiel aus den Daten: 1st Level Support bearbeitet 453 Tickets pro Woche mit einer Verweildauer von 2.4 Stunden. Schnell. Aber 9% der Tickets werden re-routed — sie gehen an ein anderes Team und kommen zurück oder werden dorthin weitergeleitet, wo sie nicht hingehören. Wenn man L1 schneller macht (mehr Leute), bearbeitet L1 mehr Tickets pro Woche. Aber der Re-Routing-Anteil bleibt bei 9%. Also kommen auch mehr falsch geroutete Tickets bei den nachgelagerten Teams an. Schneller. In größerer Menge.
Das System absorbiert die zusätzliche Kapazität, ohne dass sich die Durchlaufzeit verbessert. Erst wenn man den Re-Routing-Anteil senkt — durch bessere Kategorisierung, klarere Eskalationsregeln, Schulung — fließt die Kapazität dahin, wo sie wirkt.
Was du morgen tun kannst
Bevor du Kapazität aufbaust, beantworte drei Fragen:
Wohin fließen die Tickets? Nicht "Wie viele Tickets hat Team X?", sondern "Woher kommen sie und wohin gehen sie?" Ein einfaches Inflow/Outflow-Diagramm pro Team zeigt dir in zehn Minuten mehr als ein monatlicher KPI-Report.
Wo staut es sich? Suche nach Teams mit einem I/O-Ratio über 1.3. Dort wächst der Backlog strukturell. Nicht weil das Team schlecht arbeitet, sondern weil mehr reinkommt als rausgeht.
Ist der Stau Ursache oder Symptom? Wenn ein Team staut, weil ein vorgelagertes Team falsch routet, löst Kapazität beim stauenden Team das Problem nicht. Die Ursache liegt eine Station früher.
Drei Fragen, zehn Minuten, ein anderer Blick. Und wenn du das systematisch machen willst: Process Radar berechnet Inflow, Outflow und Kaskaden automatisch aus deinen Ticket-Daten.
Dieses Thema vertiefen: Cross-Team-Abhängigkeiten sichtbar machen: Wenn Engpässe wandern
Wo steht Ihr Service Desk im Branchenvergleich?
Der ITSM Health Check zeigt es in 2 Minuten – fünf Eingaben, keine Registrierung.
Health Check starten